Projects
spaCy projects let you manage and share end-to-end spaCy workflows for
different use cases and domains, and orchestrate training, packaging and
serving your custom pipelines. You can start off by cloning a pre-defined
project template, adjust it to fit your needs, load in your data, train a
pipeline, export it as a Python package, upload your outputs to a remote storage
and share your results with your team. spaCy projects can be used via the new
spacy project command and we provide templates in our
projects repo.

spaCy projects make it easy to integrate with many other awesome tools in the data science and machine learning ecosystem to track and manage your data and experiments, iterate on demos and prototypes and ship your models into production.
1. Clone a project template
The spacy project clone command clones an existing
project template and copies the files to a local directory. You can then run the
project, e.g. to train a pipeline and edit the commands and scripts to build
fully custom workflows.
By default, the project will be cloned into the current working directory. You
can specify an optional second argument to define the output directory. The
--repo option lets you define a custom repo to clone from if you don’t want to
use the spaCy projects repo. You can
also use any private repo you have access to with Git.
2. Fetch the project assets
Assets are data files your project needs – for example, the training and
evaluation data or pretrained vectors and embeddings to initialize your model
with. Each project template comes with a project.yml that defines the assets
to download and where to put them. The spacy project assets
will fetch the project assets for you:
Asset URLs can be a number of different protocols: HTTP, HTTPS, FTP, SSH, and
even cloud storage such as GCS and S3. You can also fetch assets using git, by
replacing the url string with a git block. spaCy will use Git’s “sparse
checkout” feature to avoid downloading the whole repository.
Sometimes your project configuration may include large assets that you don’t
necessarily want to download when you run spacy project assets. That’s why
assets can be marked as extra - by default, these assets
are not downloaded. If they should be, run spacy project assets --extra.
3. Run a command
Commands consist of one or more steps and can be run with
spacy project run. The following will run the command
preprocess defined in the project.yml:
Commands can define their expected dependencies and outputs
using the deps (files the commands require) and outputs (files the commands
create) keys. This allows your project to track changes and determine whether a
command needs to be re-run. For instance, if your input data changes, you want
to re-run the preprocess command. But if nothing changed, this step can be
skipped. You can also set --force to force re-running a command, or --dry to
perform a “dry run” and see what would happen (without actually running the
script).
Since spaCy v3.4.2, spacy projects run checks your installed dependencies to
verify that your environment is properly set up and aligns with the project’s
requirements.txt, if there is one. If missing or conflicting dependencies are
detected, a corresponding warning is displayed. If you’d like to disable the
dependency check, set check_requirements: false in your project’s
project.yml.
4. Run a workflow
Workflows are series of commands that are run in order and often depend on each
other. For instance, to generate a pipeline package, you might start by
converting your data, then run spacy train to train your
pipeline on the converted data and if that’s successful, run
spacy package to turn the best trained artifact into an
installable Python package. The following command runs the workflow named all
defined in the project.yml, and executes the commands it specifies, in order:
Using the expected dependencies and outputs defined in the
commands, spaCy can determine whether to re-run a command (if its inputs or
outputs have changed) or whether to skip it. If you’re looking to implement more
advanced data pipelines and track your changes in Git, check out the
Data Version Control (DVC) integration. The
spacy project dvc command generates a DVC config file
from a workflow defined in your project.yml so you can manage your spaCy
project as a DVC repo.
5. Optional: Push to remote storage
After training a pipeline, you can optionally use the
spacy project push command to upload your outputs to
a remote storage, using protocols like S3,
Google Cloud Storage or SSH. This can help
you export your pipeline packages, share work with your team, or cache
results to avoid repeating work.
The remotes section in your project.yml lets you assign names to the
different storages. To download state from a remote storage, you can use the
spacy project pull command. For more details, see the
docs on remote storage.
Project directory and assets
project.yml
The project.yml defines the assets a project depends on, like datasets and
pretrained weights, as well as a series of commands that can be run separately
or as a workflow – for instance, to preprocess the data, convert it to spaCy’s
format, train a pipeline, evaluate it and export metrics, package it and spin up
a quick web demo. It looks pretty similar to a config file used to define CI
pipelines.
explosion/projects/v3/pipelines/tagger_parser_ud/project.yml
| Section | Description |
|---|---|
title | An optional project title used in --help message and auto-generated docs. |
description | An optional project description used in auto-generated docs. |
vars | A dictionary of variables that can be referenced in paths, URLs and scripts and overridden on the CLI, just like config.cfg variables. For example, ${vars.name} will use the value of the variable name. Variables need to be defined in the section vars, but can be a nested dict, so you’re able to reference ${vars.model.name}. |
env | A dictionary of variables, mapped to the names of environment variables that will be read in when running the project. For example, ${env.name} will use the value of the environment variable defined as name. |
directories | An optional list of directories that should be created in the project for assets, training outputs, metrics etc. spaCy will make sure that these directories always exist. |
assets | A list of assets that can be fetched with the project assets command. url defines a URL or local path, dest is the destination file relative to the project directory, and an optional checksum ensures that an error is raised if the file’s checksum doesn’t match. Instead of url, you can also provide a git block with the keys repo, branch and path, to download from a Git repo. |
workflows | A dictionary of workflow names, mapped to a list of command names, to execute in order. Workflows can be run with the project run command. |
commands | A list of named commands. A command can define an optional help message (shown in the CLI when the user adds --help) and the script, a list of commands to run. The deps and outputs let you define the created file the command depends on and produces, respectively. This lets spaCy determine whether a command needs to be re-run because its dependencies or outputs changed. Commands can be run as part of a workflow, or separately with the project run command. |
spacy_version | Optional spaCy version range like >=3.0.0,<3.1.0 that the project is compatible with. If it’s loaded with an incompatible version, an error is raised when the project is loaded. |
check_requirements v3.4.2 | A flag determining whether to verify that the installed dependencies align with the project’s requirements.txt. Defaults to true. |
Data assets
Assets are any files that your project might need, like training and development
corpora or pretrained weights for initializing your model. Assets are defined in
the assets block of your project.yml and can be downloaded using the
project assets command. Defining checksums lets you
verify that someone else running your project will use the same files you used.
Asset URLs can be a number of different protocols: HTTP, HTTPS, FTP, SSH,
and even cloud storage such as GCS and S3. You can also download assets from
a Git repo instead.
Downloading from a URL or cloud storage
Under the hood, spaCy uses the
smart-open library so you
can use any protocol it supports. Note that you may need to install extra
dependencies to use certain protocols.
| Name | Description |
|---|---|
dest | The destination path to save the downloaded asset to (relative to the project directory), including the file name. |
extra | Optional flag determining whether this asset is downloaded only if spacy project assets is run with --extra. False by default. |
url | The URL to download from, using the respective protocol. |
checksum | Optional checksum of the file. If provided, it will be used to verify that the file matches and downloads will be skipped if a local file with the same checksum already exists. |
description | Optional asset description, used in auto-generated docs. |
Downloading from a Git repo
If a git block is provided, the asset is downloaded from the given Git
repository. You can download from any repo that you have access to. Under the
hood, this uses Git’s “sparse checkout” feature, so you’re only downloading the
files you need and not the whole repo.
| Name | Description |
|---|---|
dest | The destination path to save the downloaded asset to (relative to the project directory), including the file name. |
git | repo: The URL of the repo to download from.path: Path of the file or directory to download, relative to the repo root. "" specifies the root directory.branch: The branch to download from. Defaults to "master". |
checksum | Optional checksum of the file. If provided, it will be used to verify that the file matches and downloads will be skipped if a local file with the same checksum already exists. |
description | Optional asset description, used in auto-generated docs. |
Working with private assets
For many projects, the datasets and weights you’re working with might be
company-internal and not available over the internet. In that case, you can
specify the destination paths and a checksum, and leave out the URL. When your
teammates clone and run your project, they can place the files in the respective
directory themselves. The project assets command
will alert you about missing files and mismatched checksums, so you can ensure
that others are running your project with the same data.
Dependencies and outputs
Each command defined in the project.yml can optionally define a list of
dependencies and outputs. These are the files the command requires and creates.
For example, a command for training a pipeline may depend on a
config.cfg and the training and evaluation data, and
it will export a directory model-best, which you can then re-use in other
commands.
project.yml
If you’re running a command and it depends on files that are missing, spaCy will
show you an error. If a command defines dependencies and outputs that haven’t
changed since the last run, the command will be skipped. This means that you’re
only re-running commands if they need to be re-run. Commands can also set
no_skip: true if they should never be skipped – for example commands that run
tests. Commands without outputs are also never skipped. To force re-running a
command or workflow, even if nothing changed, you can set the --force flag.
Note that spacy project doesn’t compile any dependency
graphs based on the dependencies and outputs, and won’t re-run previous steps
automatically. For instance, if you only run the command train that depends on
data created by preprocess and those files are missing, spaCy will show an
error – it won’t just re-run preprocess. If you’re looking for more advanced
data management, check out the Data Version Control (DVC) integration.
If you’re planning on integrating your spaCy project with DVC, you can also use
outputs_no_cache instead of outputs to define outputs that won’t be cached
or tracked.
Files and directory structure
The project.yml can define a list of directories that should be created
within a project – for instance, assets, training, corpus and so on. spaCy
will make sure that these directories are always available, so your commands can
write to and read from them. Project directories will also include all files and
directories copied from the project template with
spacy project clone. Here’s an example of a project
directory:
Example project directory
If you don’t want a project to create a directory, you can delete it and remove
its entry from the project.yml – just make sure it’s not required by any of
the commands. Custom templates can use any directories they need –
the only file that’s required for a project is the project.yml.
Custom scripts and projects
The project.yml lets you define any custom commands and run them as part of
your training, evaluation or deployment workflows. The script section defines
a list of commands that are called in a subprocess, in order. This lets you
execute other Python scripts or command-line tools. Let’s say you’ve written a
few integration tests that load the best model produced by the training command
and check that it works correctly. You can now define a test command that
calls into pytest, runs your tests and
uses pytest-html to export a test
report:
project.yml
Adding training/model-best to the command’s deps lets you ensure that the
file is available. If not, spaCy will show an error and the command won’t run.
Setting no_skip: true means that the command will always run, even if the
dependencies (the trained pipeline) haven’t changed. This makes sense here,
because you typically don’t want to skip your tests.
Writing custom scripts
Your project commands can include any custom scripts – essentially, anything you
can run from the command line. Here’s an example of a custom script that uses
typer for quick and easy command-line arguments
that you can define via your project.yml:
scripts/custom_evaluation.py
In your project.yml, you can then run the script by calling
python scripts/custom_evaluation.py with the function arguments. You can also
use the vars section to define reusable variables that will be substituted in
commands, paths and URLs. In this example, the batch size is defined as a
variable will be added in place of ${vars.batch_size} in the script. Just like
in the training config, you can also
override settings on the command line – for example using --vars.batch_size.
project.yml
You can also use the env section to reference environment variables and
make their values available to the commands. This can be useful for overriding
settings on the command line and passing through system-level settings.
project.yml
Documenting your project
When your custom project is ready and you want to share it with others, you can
use the spacy project document command to
auto-generate a pretty, Markdown-formatted README file based on your
project’s project.yml. It will list all commands, workflows and assets defined
in the project and include details on how to run the project, as well as links
to the relevant spaCy documentation to make it easy for others to get started
using your project.
Under the hood, hidden markers are added to identify where the auto-generated
content starts and ends. This means that you can add your own custom content
before or after it and re-running the project document command will only
update the auto-generated part. This makes it easy to keep your documentation
up to date.
Cloning from your own repo
The spacy project clone command lets you customize
the repo to clone from using the --repo option. It calls into git, so you’ll
be able to clone from any repo that you have access to, including private repos.
At a minimum, a valid project template needs to contain a
project.yml. It can also include
other files, like custom scripts, a
requirements.txt listing additional dependencies,
training configs and model meta templates, or Jupyter
notebooks with usage examples.
Remote Storage
You can persist your project outputs to a remote storage using the
project push command. This can help you export
your pipeline packages, share work with your team, or cache results to
avoid repeating work. The project pull command will
download any outputs that are in the remote storage and aren’t available
locally.
You can list one or more remotes in the remotes section of your
project.yml by mapping a string name to the URL of the
storage. Under the hood, spaCy uses
cloudpathlib to communicate with the
remote storages, so you can use any protocol that cloudpathlib supports,
including S3,
Google Cloud Storage, and the local
filesystem, although you may need to install extra dependencies to use certain
protocols.
project.yml
For instance, let’s say you had the following command in your project.yml:
project.yml
After you finish training, you run project push to
make sure the training/model-best output is saved to remote storage. spaCy
will then construct a hash from your command script and the listed dependencies,
corpus/train, corpus/dev and config.cfg, in order to identify the
execution context of your output. It would then compute an MD5 hash of the
training/model-best directory, and use those three pieces of information to
construct the storage URL.
If you change the command or one of its dependencies (for instance, by editing
the config.cfg file to tune the hyperparameters, a
different creation hash will be calculated, so when you use
project push you won’t be overwriting your previous
file. The system even supports multiple outputs for the same file and the same
context, which can happen if your training process is not deterministic, or if
you have dependencies that aren’t represented in the command.
In summary, the spacy project remote storages are designed
to make a particular set of trade-offs. Priority is placed on convenience,
correctness and avoiding data loss. You can use
project push freely, as you’ll never overwrite remote
state, and you don’t have to come up with names or version numbers. However,
it’s up to you to manage the size of your remote storage, and to remove files
that are no longer relevant to you.
Integrations
Data Version Control (DVC)
Data assets like training corpora or pretrained weights are at the core of any NLP project, but they’re often difficult to manage: you can’t just check them into your Git repo to version and keep track of them. And if you have multiple steps that depend on each other, like a preprocessing step that generates your training data, you need to make sure the data is always up-to-date, and re-run all steps of your process every time, just to be safe.
Data Version Control (DVC) is a standalone open-source tool that integrates into your workflow like Git, builds a dependency graph for your data pipelines and tracks and caches your data files. If you’re downloading data from an external source, like a storage bucket, DVC can tell whether the resource has changed. It can also determine whether to re-run a step, depending on whether its input have changed or not. All metadata can be checked into a Git repo, so you’ll always be able to reproduce your experiments.
To set up DVC, install the package and initialize your spaCy project as a Git and DVC repo. You can also customize your DVC installation to include support for remote storage like Google Cloud Storage, S3, Azure, SSH and more.
The spacy project dvc command creates a dvc.yaml
config file based on a workflow defined in your project.yml. Whenever you
update your project, you can re-run the command to update your DVC config. You
can then manage your spaCy project like any other DVC project, run
dvc add to add and track assets
and dvc repro to reproduce the
workflow or individual commands.
Prodigy
Prodigy is a modern annotation tool for creating training
data for machine learning models, developed by us. It integrates with spaCy
out-of-the-box and provides many different
annotation recipes for a variety of NLP tasks,
with and without a model in the loop. If Prodigy is installed in your project,
you can start the annotation server from your project.yml for a tight feedback
loop between data development and training.
The following example shows a workflow for merging and exporting NER annotations collected with Prodigy and training a spaCy pipeline:
project.yml
The train-curve recipe is another
cool workflow you can include in your project. It will run the training with
different portions of the data, e.g. 25%, 50%, 75% and 100%. As a rule of thumb,
if accuracy increases in the last segment, this could indicate that collecting
more annotations of the same type might improve the model further.
project.yml (excerpt)
You can use the same approach for various types of projects and annotation workflows, including named entity recognition, span categorization, text classification, dependency parsing, part-of-speech tagging or fully custom recipes. You can also use spaCy project templates to quickly start the annotation server to collect more annotations and add them to your Prodigy dataset.
Streamlit
Streamlit is a Python framework for building interactive
data apps. The spacy-streamlit
package helps you integrate spaCy visualizations into your Streamlit apps and
quickly spin up demos to explore your pipelines interactively. It includes a
full embedded visualizer, as well as individual components.
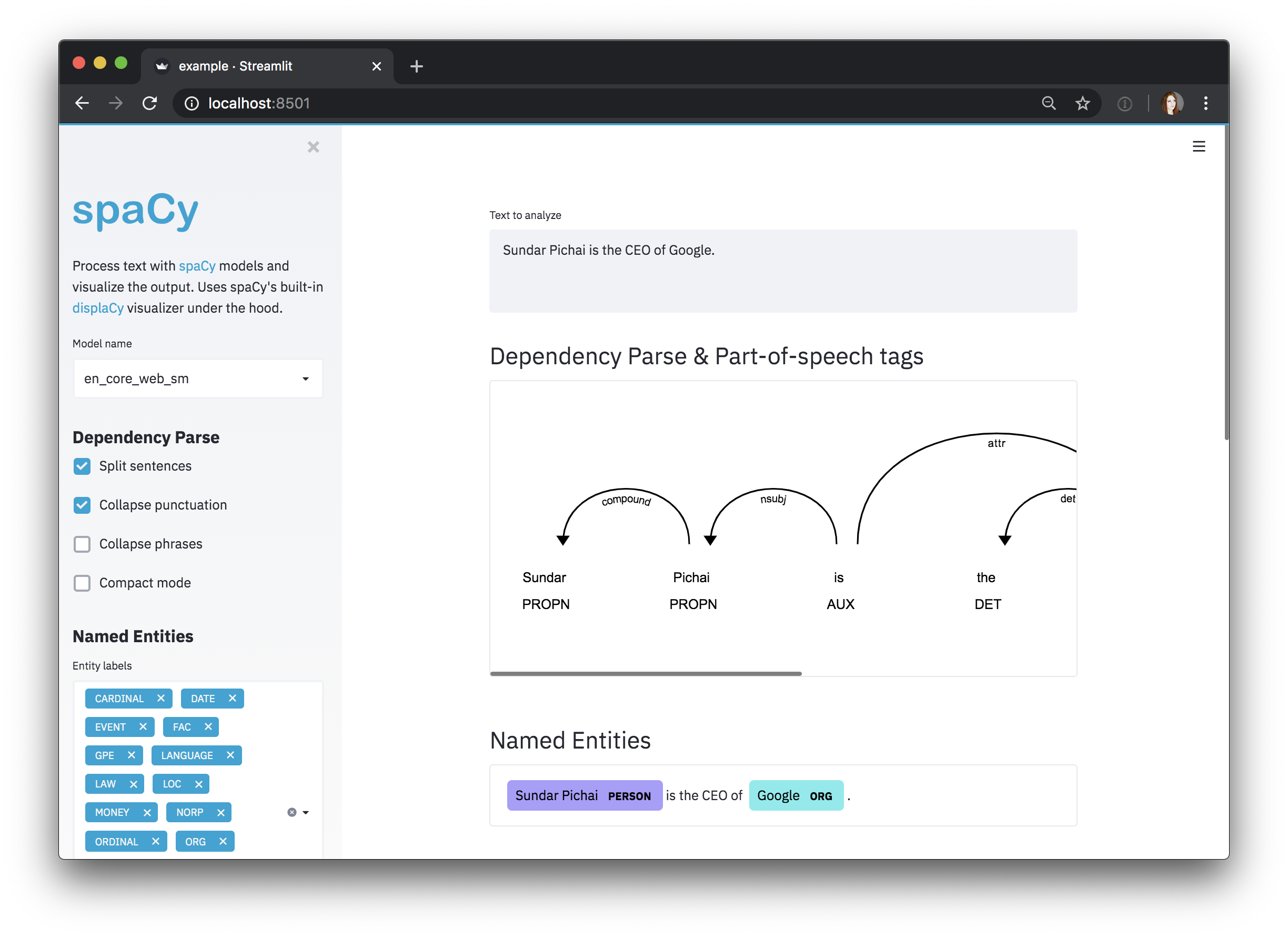
Using spacy-streamlit, your
projects can easily define their own scripts that spin up an interactive
visualizer, using the latest pipeline you trained, or a selection of pipelines
so you can compare their results.
project.yml
The following script is called from the project.yml and takes two positional
command-line argument: a comma-separated list of paths or packages to load the
pipelines from and an example text to use as the default text.
explosion/projects/v3/integrations/streamlit/scripts/visualize.py
FastAPI
FastAPI is a modern high-performance framework for building REST APIs with Python, based on Python type hints. It’s become a popular library for serving machine learning models and you can use it in your spaCy projects to quickly serve up a trained pipeline and make it available behind a REST API.
project.yml
The script included in the template shows a simple REST API with a POST
endpoint that accepts batches of texts and returns batches of predictions, e.g.
named entities found in the documents. Type hints and
pydantic are used to define the
expected data types.
explosion/projects/v3/integrations/fastapi/scripts/main.py
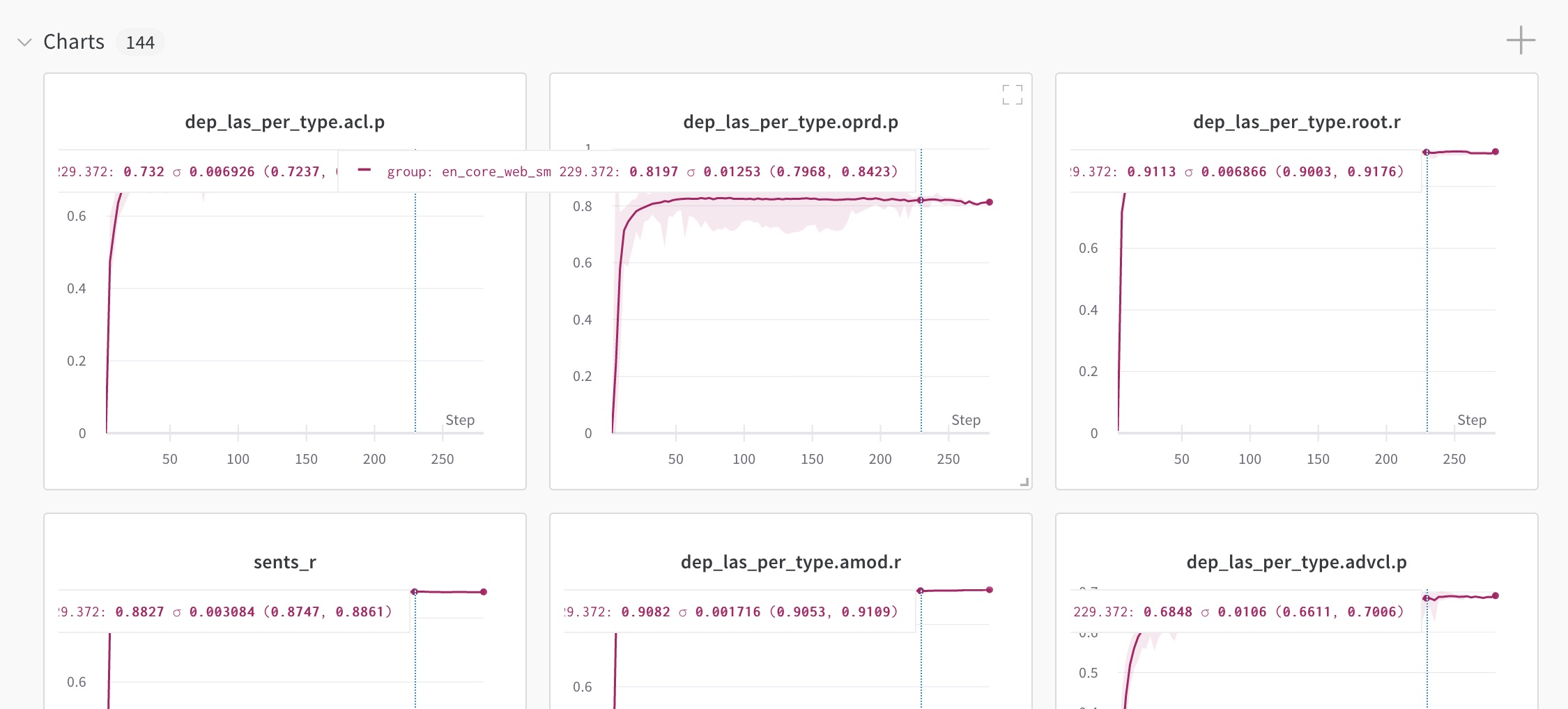
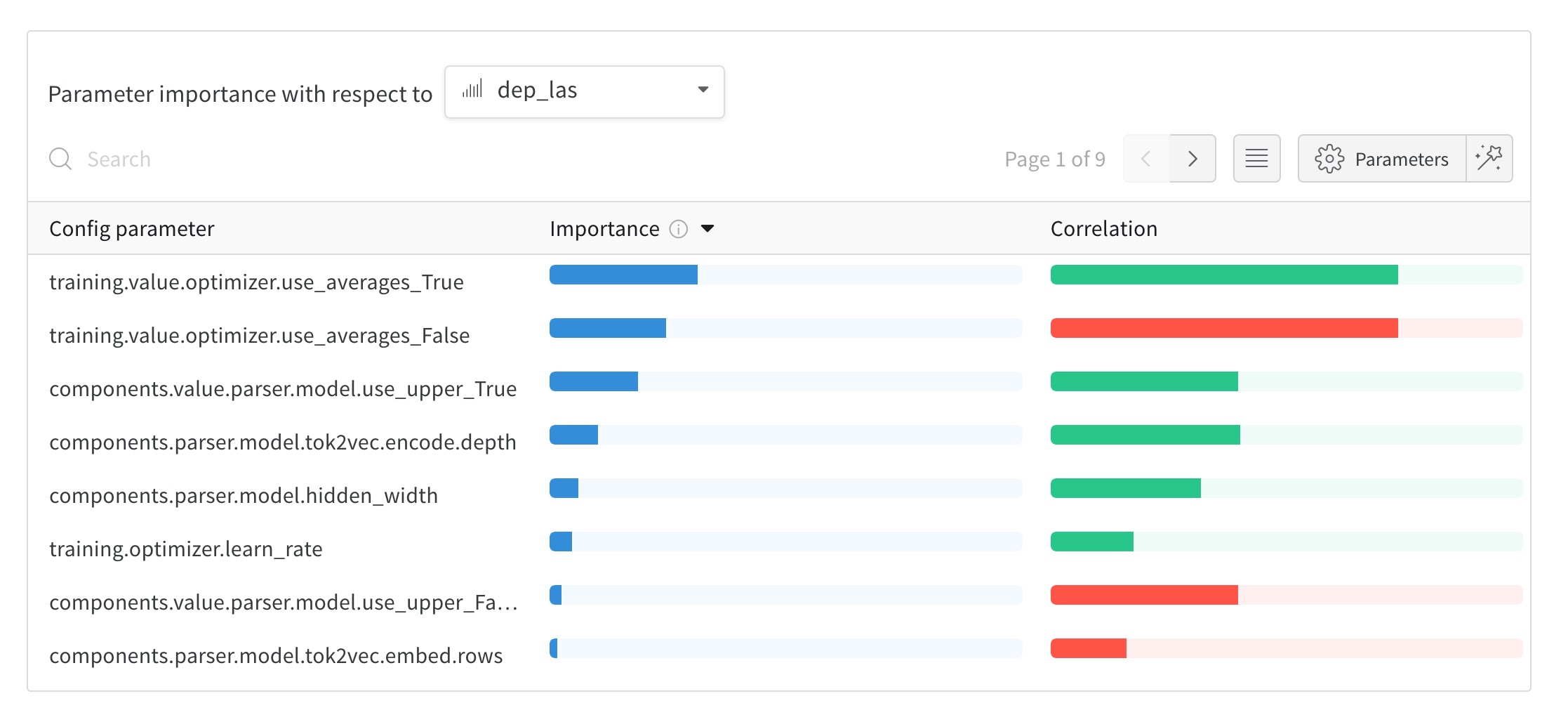
Weights & Biases
Weights & Biases is a popular platform for experiment
tracking. spaCy integrates with it out-of-the-box via the
WandbLogger, which
you can add as the [training.logger] block of your training
config. The results of each step are then logged in
your project, together with the full training config. This means that
every hyperparameter, registered function name and argument will be tracked
and you’ll be able to see the impact it has on your results.
Hugging Face Hub
The Hugging Face Hub lets you upload models and share
them with others. It hosts models as Git-based repositories which are storage
spaces that can contain all your files. It support versioning, branches and
custom metadata out-of-the-box, and provides browser-based visualizers for
exploring your models interactively, as well as an API for production use. The
spacy-huggingface-hub
package automatically adds the huggingface-hub command to your spacy CLI if
it’s installed.
You can then upload any pipeline packaged with
spacy package. Make sure to set --build wheel to output
a binary .whl file. The uploader will read all metadata from the pipeline
package, including the auto-generated pretty README.md and the model details
available in the meta.json. For examples, check out the
spaCy pipelines we’ve uploaded.
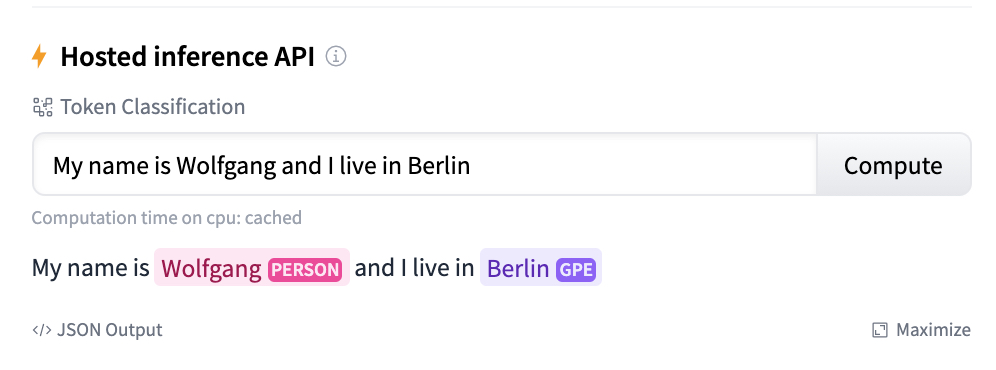
After uploading, you will see the live URL of your pipeline packages, as well as
the direct URL to the model wheel you can install via pip install. You’ll also
be able to test your pipeline interactively from your browser:
In your project.yml, you can add a command that uploads your trained and
packaged pipeline to the hub. You can either run this as a manual step, or
automatically as part of a workflow. Make sure to set --build wheel when
running spacy package to build a wheel file for your pipeline package.
project.yml